




Database performance is a crucial part of any application. As databases and the tables within them get larger, though, performance starts to drop – here’s why that happens and how to fix the problem.
Database performance is an issue to every developer an DBA alike – and with larger tables, the issue often gets even worse. Feel free to explore StackOverflow for answers to the questions related to big data and databases – can you even count how many questions users usually come up with? Yeah, we can’t either. Big data is one of the core use cases of both relational and non-relational databases alike: the more data we have, the bigger the issue of managing them properly becomes. So, why does our database performance drop when large tables are in use?
Understanding Big Data
To answer that question, we need to understand big data in and of itself. Big data, as defined by multiple sources, refers to data sets that are so large that usual shared hosting or VPS servers are too weak to deal with. Furthermore, big data sets are often used for data analytics – analyzing big data sets often reveals patterns and trends within them that can be used as part of a blog, business presentation or an investor pitch.
And herein resides the problem as well – as there is more and more data on the web, working with it is a hassle for many. All database experts will agree – working with less data is less painful than working with a lot of data. The reason why is plain and simple – the more data we have, the more problems occur. Problems are not only related to database performance, but they may also cover availability, capacity, and security issues. Glue everything together and you will have an extremely serious problem on your hands – fixing it before it drowns you would be great.
Databases and Big Data
As far as databases and big data is concerned, the first problem lies in the poor choice of a database management system. Many are automatically drawn to non-relational database management systems like MongoDB, but before making a decision, we definitely need to evaluate all of the parameters:
Do we need ACID or BASE compliance? Relational database management systems like MySQL are great at the former, while MongoDB would be great for the latter.
What do we consider big data? Do we have 20 or 200 million rows? Perhaps 2 billion rows? Is our data projected to grow expontentially or do we think that working with 10 billion rows would cut the chase?
Have we ever worked with big data before? Were there any mistakes that we made along the way that we can learn from? How was our experience with one or the other database management system?
Do we have experience tuning database management systems? What database management systems are they? Believe it or not, all database management systems are made in a similar fashion. Learn how to optimize TimescaleDB and you will know your way around Oracle, MongoDB, and MySQL at least a little.
The first question is perhaps the most important – ACID compliance would be great if we want data consistency at the price of slower insert speeds, while BASE compliance would be great if we’d rather sacrifice consistency, but work with JSON-based data at the same time.
Choosing a database management system to base our big data project on is also very crucial – after weighing the first question, though, the path becomes clear: there are only a couple of DBMSes that support ACID or BASE parameters, so we’ll need to choose from them. If we have experience working with the database management system, that’s great – if not, well, we will have to learn.
After we’ve chosen a database management system according to our requirements, it’s time to get to the main question – why is it slow when working with large tables?
Why Are Our Databases Slow?
The most complex questions require the simplest answers – believe it or not, everything’s the same way as far as databases are concerned as well. Our databases are slow for one or more of the following reasons:
We scan through too much data – believe it or not, many people who find themselves having problems with database performance on big data scan through billions of records when they may only need thousands or millions. See the problem? Yeah.
Our database or the queries querying it don’t make use of partitions, indexes, or are implemented in a flawed way – what’s the use of partitions or indexes when our queries aren’t even using them? Yup, none.
Our databases or the server behind them isn’t optimized for big data – having chosen a proper DBMS for our specific use case is great, but if we run our project on a shared hosting infrastructure, can we expect good results? Can we expect results at all? Database isn’t even the problem at that point – ramp up your server game, then look at the database front.
We have chosen the wrong database management system for our use case – if we only know how to work with MongoDB but choose MySQL as our primary DBMS of choice, we’ll need to put in some work to figure out how it works and why it works the way it does; without us putting in the work, we won’t be able to optimize it, and without optimizing it, we will have problems not only on the big data front, but probably everywhere else as well.
Optimizing Our Servers
Before embarking on any kind of a project, all DBAs and developers should turn to their servers to see whether they can even run big data sets the way they require. MySQL will be a great choice for those who need ACID compliance, while MongoDB will be better for those who need Basically Available, but Eventually Consistent (BASE) data-based projects, but servers are important too – do we have so much data that using a dedicated server is necessary or will we make use of a VPS instead?
It would be great to start from a VPS and switch to a dedicated when the situation requires us to – that way, we save money and don’t waste resources as well.
Choosing a server is only one piece of the puzzle though – after we have chosen a DBMS for our project, it’s time to optimize it as well. Turn to the documentation and read the performance paragraphs thoroughly – in many cases, you will see that the database management system that you’ve elected to use has multiple storage engines that are available for you to choose from. Different storage engines will work differently as well: did we mention that all database storage engines can be optimized in files that allow for the optimization of all of the parameters within databases as well?
These files are as follows:
Postgresql.conf for those working with PostgreSQL.
my.cnf for those working with MySQL, MariaDB, or Percona Server (for Windows users, my.cnf will be called my.ini.)
Mongod.cfg for those working with MongoDB.
ConfigurationFile.ini for those working with Microsoft SQL Server.
Get the grip already? Now turn to the documentation once again to decide which storage engine you should use and optimize the necessary parameters for performance, availability, security, and capacity. You may want to do everything in a local environment first as there will surely be some space for errors to occur.
Optimizing Searching for Data
Now that you’ve decided what database management system to employ and optimized all of the necessary parameters, optimize searching for data or you will be heading for trouble as well. Keep the following aspects in mind:
Aim to search through as little data as possible – that means instead of using queries like
SELECT *, aim to build them in a way that selects only the necessary columns: perhapsSELECT idwould be enough?Make sure your queries use indexes – what’s the point of using indexes if your queries don’t even use them?
If you use B-tree indexes, use
WHEREclauses while searching for an exact match.If you elect to use
FULLTEXTindexes, make use of their capabilities including searching in various modes, the wildcard character if necessary, etc.If you use indexes, avoid having the wildcard character at the beginning of the query because this is what slows your database down in most cases. If you have a necessity to use a wildcard, employ it at the end of your statement like so – for smaller tables, the result may not be noticeable, but for bigger ones it can seriously be very substantial:
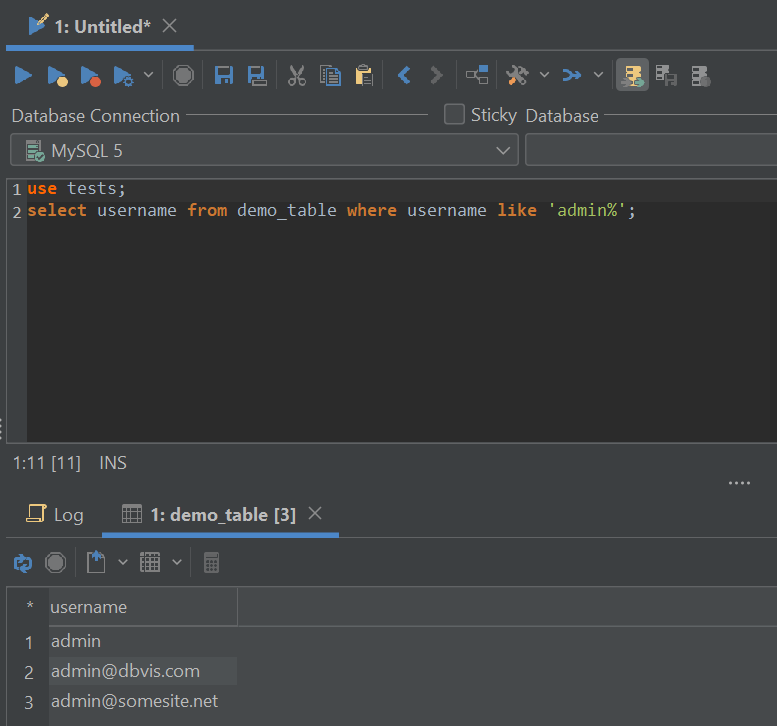
Use of a wildcard at the end of your statement.
Where possible, partition your tables – partitions, like indexes, sacrifice space for performance. If you’re familiar with the types of partitions available within your database management system of choice (many DBMSes offer partitioning by RANGE, LIST, HASH, KEY, or other mechanisms), it shouldn’t be hard to come up with a solution that fits your use case almost like a glove. If you have doubts, refer to the documentation of your database management system of choice or have a read through blogs belonging to SQL clients such as DbVisualizer.
Avoid DISTINCT or UNION queries – these kinds of queries cost extra operations to the database and chances are it’s already jumping through hoops to save the day anyway. Use such operations only if necessary – perhaps you can do operations that make use of
DISTINCTcolumns locally and run multiple queries one after another without using theUNIONclause that joins queries together?Keep in mind that queries searching for NULL values can also be optimized – include an
IS NULLcondition in yourWHEREclause if you want to search for null values in a specific column and also keep in mind that ifNULLvalues are used with partitioning in certain database management systems (MySQL comes to mind), values containing NULL will always be at the lowest partition possible, so don’t bother searching through other partitions to find the values.Use a proper character set and collation for your use case – do you know how many DBAs worth their salt make a mistake of using an improper character set or collation? Too many. So many, in fact, that all database management systems have documentation around that issue. We can’t tell you what you should use in all use cases, but for most of us working with data, utf8mb4 (utf8, just with 4 bytes per character to support Unicode) will do.
Optimizing Database Management
Optimizing servers and queries is great – there’s one more step you need to take to feel at ease though. That step refers to the optimization of database operations with SQL clients or database management tools. One of such tools is DbVisualizer – the tool is being used by top-notch companies across the globe including Uber, Google, Volkswagen, Netflix, Twitter, Tesla, NASA, amongst others, it has millions of users, and it’s built for managing complex database environments meaning that managing database management systems while working with big data sets will be a breeze – here’s how DbVisualizer can help you visualize the data in your databases in the form of a nice graph. Not only that, but DbVisualizer will also help you optimize your databases and do other work as well – did we mention that DbVisualizer users can visualize data through Microsoft Excel as well?
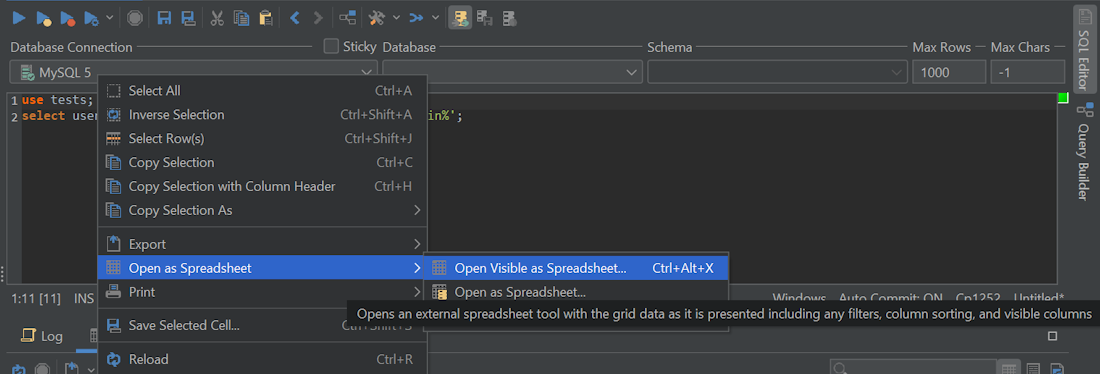
Visualizing data with DbVisualizer.
Once all three aspects – servers, searching for data, and database management operations – are optimized, we should remember that we should always keep an eye on our databases with SQL clients and database management software such as the one provided by DbVisualizer – keeping up with the news in the database space is also easier than ever so make sure to do that, evaluate the tool for your use case, and until next time!
FAQs
Why are My Databases Slow?
Your databases are most likely slow because of one or more of the following reasons:
You select too many rows and/or columns – selecting one or two is usually enough. Do you really need to select everything?
Your database isn’t properly optimized for performance (you don’t use all of the necessary settings to optimize its performance) – have you optimized my.cnf? postgresql.conf? No? Well, here’s the problem.
Your database isn’t normalized or your servers are not fit for the purpose – good servers take your databases further than you could ever imagine. Avoid using shared hosting when running big data – at the very least, consider using a VPS.
How Do I Optimize Searching for Data?
Consider selecting as few rows as possible, as well as partitioning and indexing your tables where necessary.
What Kind of DBMS Should I Work With?
Everything depends on your requirements for a specific project – if you work with unstructured data, MongoDB databases will do, however, if you want to work with relational databases, look into MySQL or its counterparts.
About the author
Lukas Vileikis is an ethical hacker and a frequent conference speaker. He runs one of the biggest & fastest data breach search engines in the world - BreachDirectory.com, frequently speaks at conferences and blogs in multiple places including his blog over at lukasvileikis.com.